
电脑里的中文:字符集、键盘与输入法
⓪ 前言
为何会想到要写这篇博客呢?其实是因为最近在折腾一些输入法相关的事情,包括给我的Windows和Arch装了Rime,给手机装了Trime;以及在学习/练习小鹤双拼。
① 字符集 Charset
一个众所周知的事实是:计算机里只有0和1。但是许多人不知道的是:这些0和1如何形成了我们如今看到的计算机上的各种软件?
字符集就是其中的一个重要手段,它把这些0和1的组合与我们见到的字母、符号、文字,乃至emoji和某些控制命令一一对应。
在至今仍被广泛提起的字符集中,ASCII绝对是当之无愧的元老。它于上世纪60年代被“发明”(或者应该说“规定”?)出来,将英文的26个字母的大、小写,常见的一些标点符号,10个数字以及一些特殊的控制字符映射到了0x00~0x7F上。事实上现在很少有软件仅支持ASCII了,但是后续的GBx/BIG5/UTF-8/ShiftJIS/Windows-1252等字符集都跟随了权威,对ASCII支持兼容。
计算机技术在遥远的东方推开的过程中,很快遇到了一个问题:ASCII字符集只有英文字母数字标点,没有中文汉字(当然,同时也没有韩文日文藏文希腊字母西里尔字母等等等等)。因此,编写一个支持中文的字符集成为了当务之急。
1980年,中国发布了第一个汉字编码标准,即大名鼎鼎的GB2312标准(来自GB/T 2312-1980的缩写)。这个标准支持6763个常用汉字,可以覆盖大部分日常使用场景。
然而,GB2312同时也缺少了很多不那么常用的字,在使用中时不时还是会遇到。因此之后又开发了GBK(国标-扩)和GB18030(来自GB
18030-2022的缩写)两个编码库,分别支持两万多和七万多汉字和字符,还支持一些日韩语中的汉字以及少数民族的名字和文字。这些编码是向前兼容的:如果一个文档最初以GB2312编写和保存,你用GBK以及GB18030去读取是完全正常的。而如果一个文档最初以GB18030编写和保存,用GB2312去读取,则会在GB2312覆盖的范围内正常显示,对GB2312没覆盖到的字符显示为问号字符?或�,或者直接报错。
然而国标码虽然在国内满足了需求,但是当信息跨国通讯时,不同字符集对同一个字码会有不同的解释,这就带来了许多困扰。为了解决信息跨国、跨大洲流动时的译码问题,就需要定义一个全世界范围内通用的字符集标准。于是,在1994年,Unicode统一码/万国码的首个版本正式发布了。
Unicode包含很多种实现方式,其中最为知名最为广泛使用的就是大名鼎鼎的UTF-8(因为它是Unicode中唯一兼容ASCII的……)。Unicode包含的字符极为广泛,从世界各种文字,到各种符号乃至emoji,还有许多控制字符,可以把已有的Unicode字符组合起来产生新的。基本上可以说,UTF-8就是现在世界范围内绝对主流的字符集。
Unicode虽好,但是却与国标码不兼容。不管是以UTF-8方式读取国标码文档,还是以国标码方式读取UTF-8文档,都会导致乱码。而且有时在读取过程中编辑器会帮你自动做一些处理,如果你在错误的方式下让编辑器重新保存了文档,有时还会导致原来的正确编码打开依然还是乱码。这也就是著名的“锟斤拷”“烫烫烫”等名梗的来源:
- “锟斤拷”:当你用UTF-8打开一个本是GBK编码的文本,解码器遇到无法识别的字节序列时,会用一个特殊字符
�(U+FFFD,即Replacement Character)来代替。这个�字符在UTF-8中的编码是三个字节0xEF 0xBF 0xBD。如果连续出现多个�,比如两个�挨着,它们的原始字节序列就是EF BF BD EF BF BD。此时,如果你又错误地用GBK去解释这串字节,那么EF BF会被解码为“锟”,BD EF解码为“斤”,BF BD解码为“拷”,于是你就看到了经典的“锟斤拷”。 - “烫烫烫”:这个梗主要出现在Windows的Visual
C++编译器中。在Debug模式下,编译器会把未初始化的栈内存全部填充为
0xCC,未初始化的堆内存填充为0xCD。而在GBK字符集中,连续两个0xCC恰好对应“烫”字,0xCD 0xCD对应“屯”或“?”(不同版本略有差异)。所以当你打印出未初始化的局部变量数组时,屏幕上就可能刷出一长串“烫烫烫烫”,像是内存“发烧”了一样。
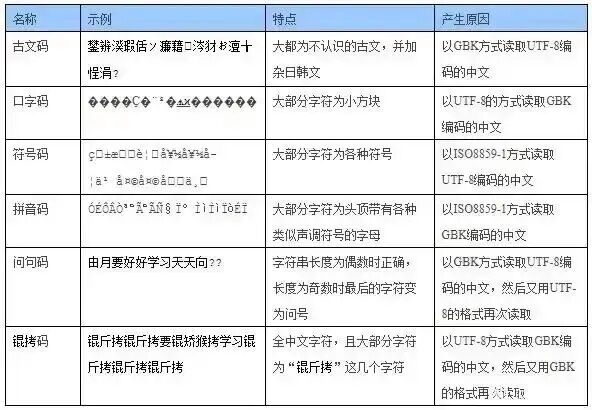
然而,Windows中文发行版的终端默认使用的还是国标系列字符集。这就导致如果你用UTF-8撰写了代码,那么在编译和运行时其中的汉字会出现乱码问题。同时这也是为什么我们建议Windows的用户名和路径名不要使用非ASCII字符,因为你永远不知道会在什么时候被背刺一下。当然,Windows的终端也提供了更换字符集的命令chcp。把chcp 65001写进终端的profile在每次启动时执行一下,就可以使用UTF-8的终端了。
② 键盘 Keyboard
中文键盘的问题的历史可不比字符集的问题短。英文字母由于个数有限,可以比较简单地做出机械结构的打字机,而中文仅常用字就成千上万,打字机比较不好做。纯机械结构的尝试包括周厚坤的索引打字机、舒震东的舒式打字机等。在电子技术发展了之后,又出现了林语堂的明快打字机,采用72键输入,输入两个字根后会显示8个候选字,再用数字键选择。
进入计算机时代,中文打字的问题反而得到了简化,不再需要准备那么多的铅字待选中,只要把要打的字跟字符集里的代码对应起来就行了。这时的中文键盘大致可以分为三种:
- 整字大键盘:每个键都是一个字,按下键直接输入字,好处是所见即所得,坏处则是键盘过于庞大,造价高昂,并且找字比较麻烦,而其键盘上没有的字就永远输入不了了。
- 拆字键盘:把汉字拆成字根,利用主键和辅键组合选字。优点是需要的按键数量比整字大键盘大大减少,缺点则是学习成本比较高。
- 复用英文键盘:直接把英文键盘搬来复用,通过特定的编码来输入汉字。优点是只要开发软件即可,不用开发键盘硬件。复用法最终成为了主流方案。
③ 输入法 Input Method
既然决定了采用复用英文键盘的路径,那就要找到合适的方案,把输入的按键排列映射成汉字。
一个显然的思路就是用音码,既然已经有汉语拼音/威妥玛拼音/注音等标记汉字读音的方式,那就把拼音字母/注音字母映射到键盘上就好了。拼音字母由于本身就是英文字母(除了ü以外),那么只要一一映射就可以了(把ü安排到v的位置上)。注音稍微麻烦一点,因为注音字母一是数量比英文字母多,二是符号也是完全独立的一套体系,所以不仅要使用键盘上的英文字母区,还要借用一些符号区和数字区的按键。
另一个思路是按照字形来输入。把汉字拆成笔画与部件,把每个部件/笔画都映射到按键上,按一定顺序输入即可出字。典型的形码包括1976年朱邦复的仓颉输入法,以及1983年王永民的五笔输入法。
从输入效率的角度来说,形码的上限比音码要高不少,因为汉语中有大量的同音字,拼音/注音的映射会有大量的重码,在输完音码之后还要花时间选择,而形码的重码率相当低。然而随着输入法的不断智能化(如微软与哈工大合作的微软拼音输入法,北大朱守涛的智能ABC输入法,以及再之后搜狗输入法的崛起),整词输入取代了单字输入,智能联想功能大幅缓解了音码的重码问题,而形码则因为学习曲线比较陡峭而渐渐没落。
然而全拼的音码输入法依然有一个很大的缺陷,就是击键次数过多。与之相对地,另一种音码输入法–双拼输入法,则大幅减少了击键次数。双拼输入法的基本思路很简单:大部分汉字的发音都是“声母+韵母”的组合,其中声母字母种类较多但是长度短,韵母用到的字母种类较少但是长度长,全拼的击键次数过多很大程度上是因为韵母太长了,那么为什么不把这些长长的韵母一个一个重新映射到键位上呢?双拼输入法做的就是:让声母只按一个键,韵母也只按一个键;如果是单韵母发音的汉字,则也按某种规则映射成两个键,形成一种“两键一字”的固定格式。双拼输入法与全拼相比大幅减少了击键次数,一定程度上提高了输入效率,同时学习难度也不像形码那样高。
不过双拼输入法依然是基于音的输入法,这就注定了它不能解决重码的问题。为此,又有人把形码重新拉了回来,做成了音与型结合的音形码:先用音码确定读音,再用字的开头和结尾对应的形码去筛选字形,尽量做到降低击键数的同时减少重码。
④ 移动端
进入智能手机时代,中文输入法又面临了一次新的挑战:屏幕太小,无法完整放置26个字母键。于是,两种主流的虚拟键盘布局应运而生:
九宫格(T9):将字母分到3×3的9个按键上,每个按键对应3~4个字母。优点是按键面积大,盲打效率高,缺点是重码率极高。例如按“226”可以对应“ban”“cam”“bao”等多种拼音组合。好在手机输入法可以借助词库和上下文联想来大幅降低选词成本,使得九宫格在拼音用户中依然非常流行。
全键盘(QWERTY):在手机上完整保留26个字母键,每个按键非常狭小,但支持点划、滑动等操作。对于双拼和形码用户来说,全键盘几乎是唯一选择,因为他们需要精确区分每个字母。
除了九宫格和全键盘,移动端还存在一些折中方案,试图在按键面积和重码率之间找到平衡:
14键布局(如T+2、双拼键盘):将26个字母分配到14个按键上,常见于第三方输入法的“双拼专用键盘”或“笔画+拼音混合键盘”。例如,百度输入法和搜狗输入法都提供过14键拼音模式,把声母和韵母按使用频率分组,每个键位对应1~2个字母,比九宫格重码少,又比全键盘按键大。对于双拼用户来说,14键更加自然——因为双拼本身就是“声母一键+韵母一键”,14个键刚好可以覆盖所有声母和韵母的映射(如小鹤双拼中,v代表zh,u代表sh,i代表ch,其余字母基本保留)。许多双拼用户会在手机上切换到14键布局,享受比全键盘更大的点按区域。
12键布局(NEO、Morse等):更少见的实验性布局,例如将字母按笔画形状或摩斯码规律分组。这类布局通常需要用户专门学习,几乎没有主流输入法默认提供,但在某些极客社区(如Rime方案分享)中偶有讨论。
自适应布局:根据当前输入的上下文动态调整按键大小或排列。例如,当你输入“w”后,系统预测下一个字母可能是“o”或“e”,于是自动放大这两个按键的区域。这种布局尚未成为主流,但代表了输入法向个性化、智能化发展的一个方向。
在众多移动端布局中,14键是目前双拼用户最青睐的选择之一。它既不像九宫格那样让双拼的“每个声母/韵母独占一键”的优势无法发挥(九宫格中一个键对应多个字母,双拼的确定性会被破坏),也不像全键盘那样容易误触。如果你在电脑上习惯了小鹤双拼,在手机上开启14键双拼模式,几乎可以无缝迁移肌肉记忆。
移动端还催生了两种独特的输入方式:
滑行输入(Swype / Glide Typing):手指在字母间连续滑动,经过组成单词/拼音的所有字母,算法根据轨迹自动识别出可能的输入。对于英文非常高效,对于中文拼音也有一定的支持(如百度输入法的“滑动输入”)。
语音输入:随着语音识别技术的成熟,语音输入在移动端的使用体验远好于桌面端。尤其对于长文本输入或手头不方便打字时,“说”比“打”快得多。但语音输入在安静环境或方言口音下仍有局限。